Kudu学习记录
1.概述
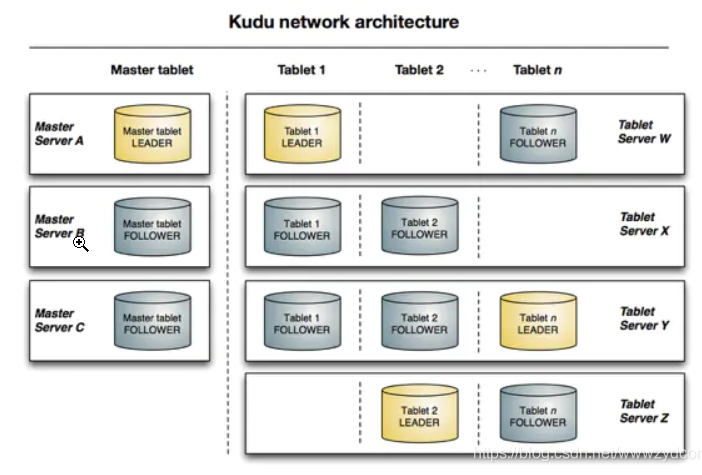
如上所示是kuda的基本架构,kuda也是典型的主从架构,一个kuda集群有主节点(master)和若干个从节点(table server)组成。master负责管理集群的元数据(类似hbase master),tablet server负责数据存储(类似hbase regionserver)。在生产环境中,一般会部署多个master实现高可用(奇数个,一般为三个),tabletserver一般也是奇数个。
2.kudu的基本术语
table(表)
table和其他关系型数据库的一样。table是数据存储在kudu的位置,table会被宰水平分成很多段,每个段称为tablet。
tablet
一个tablet是一张表中连续的segment(片段),类似于hbase中的region,或者是关系型数据库中的partition分区。每一个tablet都存储着一定连续range的数据,同时一张表上的两个tablet上的range不会重叠,一张表的所有tablet会包含这个表的所有range;同时在分布式系统上,kudu的tablet也是有冗余设置,同一个tablet会存储多份,存放在多个不同的tablet server上面,并且在任何一个给定的时间点,其中只有一个tablet server是leader,其他的都是follwer tablet,每个tablet都可以提供读请求,但是只有leader可以负责写请求。
tabletserver
tabletserver是kudu集群中的从节点,负责数据存储,并提供数据读写服务,一个tablet server存储了table表中的tablet,同时一个tabletserver中存储了多个不同的tablet,同一个tablet的不同备份也会存在与不同的tabletserver上面,当一个tablet在该tabletserver上市leager,则其他tabletserver从当该tablet的follower副本。
master
集群的主节点,负责集群管理,元数据管理等功能,保持跟踪所有的tablets,tabletservers,catalog tagbles(目录表)和其他与集群相关的meta data。同样的在同一个时间也只有一个起作用的master(也就是leader),如果当前的leader消失了就选举一个新的leader,会通过raft协议来进行选举(todo:后面来看raft协议)。
raft consensus algorithm
kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft协议,tablet 的多个副本选举出 leader,它负责接受请求和复制数据写入到其他follower副本。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组N副本(通常为 3 或 5 个)能够接受最多(N - 1)/2 错误的副本的写入。
Catalog Table(目录表)
catalog table是kudu是元数据表,它存储有关tables和tablets的信息.catalog table(目录表)不能被直接读写,它只能通过客户端 API中公开的元数据操作访问。
catalog table存储以下两类元数据:
1、tables:table schemas 表结构,locations 位置,states 状态
2、tablets:现有tablet 的列表,每个 tablet 的副本所在哪些tablet server,tablet的当前状态以及开始和结束的keys(键)。
3.语法
使用impala创建表:必须首先列出构成主键的列
1 | CREATE TABLE my_first_table |