Hive学习记录
1.概述
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转化成Mapreduce任务进行,可以通过类sql的语句快速地实现MapReduce统计,不必开发专门的MapReduce应用,Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据,在hadoop之上,总归为大数据。Hive的表其实就是HDFS的目录/文件,按照表名把文件夹分开,如果是分区表,那么分区值就是子文件夹,可以直接砸MP job里使用这些数据。
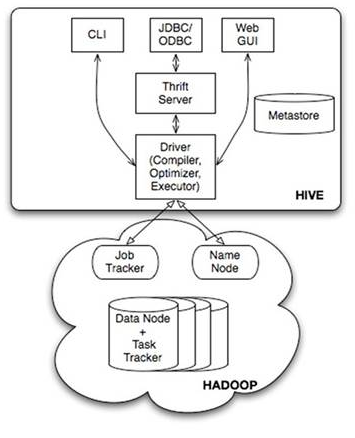
2.Hive系统架构
CLI,即为shell命令行
JDBC、ODBC 是Hive的java,与JDBC相似
WebGui是通过浏览器访问hive。
Metastore组件:hive将元数据存储在metaStore中,目前只支持mysql,derby,Hive中的元数据包括表的名字,表的列和分区以及属性,表的属性(是否为外部表),表的数据所在的目录。同时Metastore主要由两部分组成:Metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。metastore服务是建立在后台数据存储介质之上的,并且可以和hvie服务进行交互的服务组件,默认情况下metaStore服务是和hive服务安装在一起的,运行在同一个进程中。但是也可以让metaStore服务独立安装在一个集群中,hive远程调用metaStore服务。
解释器,编译器,优化器完成HQL查询语句从词法分析,语法分析,编译,优化以及查询计划的生成。生成的查询计划存储在HDFS中,并随后有MapReduce来调用执行。

相当于用户写的sql经过hive转换成mapreduce,再调用hadoop中的mp,去调用hdfs中的数据进行查询任务。
3.和传统数据库的对比
| Hive | ReBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or local FS |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 大 | 小 |
| 处理数据规模 | 大 | 小 |
| 索引 | 0.8之后加入了位图索引 | 有复杂的索引 |
hive中的所有数据都是存储在HDSF中,没有专门的数据存储格式,可以支持Text,Sequencefile,ParquetFile,RCFILE等。需要在建表的时候配置hive数据中的列分隔符和行分隔符,hive就可以解析数据。Hive中的数据模型主要包括:DB,Tabel,External Table,Partition,Bucket。db是在hdfs中表现为${hivem.metastore.warehourse.dir}目录下一个文件夹。table是db目下一个文件夹。external table外部表和table类似,不过其数据存放位置可以在任意指定路径。普通表删除表后,hdfs上的文件就删除了,外部表删除后,hdfs上的文件没有删除,之事把文件删除了。partition在hdfs中表现为在table目录下的子目录。bucket桶在hdfs中表现为同一个表目录下根据hash散列之后的多个文件,会根据不同的文件把数据放在不同的文件中。hive表的数据是分为两部分的一部分是存放在hdfs上面的data,一部分是存放在mysql上面的data。